Today’s world is a world of big data. Big data means lots
and lots of data. To understand this data, one needs to analyze it and to make
it understand to people who are not related to the data, one needs to present
it. Hence, data visualization has gained prime importance in conveying
information to people. Complex problems can be understood by data visualization
as it shows how different data are related to each other. Data visualization is the presentation of data in
a pictorial or graphical format. It enables decision makers to see analytics
presented visually, so they can grasp difficult concepts or identify new
patterns.
Following are some of the examples of data visualization
techniques in different lines of business:
1.Healthcare
The above graph has different colors for different countries
and every country’s data in a certain age bracket. This is an excellent way to
represent data as it gives us the distribution country wise, age wise and cost
wise, all in one graph.
2. Technology
The above dashboard shows different ways in which the sales
can be depicted. The bar graph very conveniently shows both the sales and the
goals for that month. It makes it very easy to compare the sales to goal
ration. The map is used to depict sales by region with the color indicating
density. A simple pie chart is used to show the sales breakdown by product since
only percentages matter here.
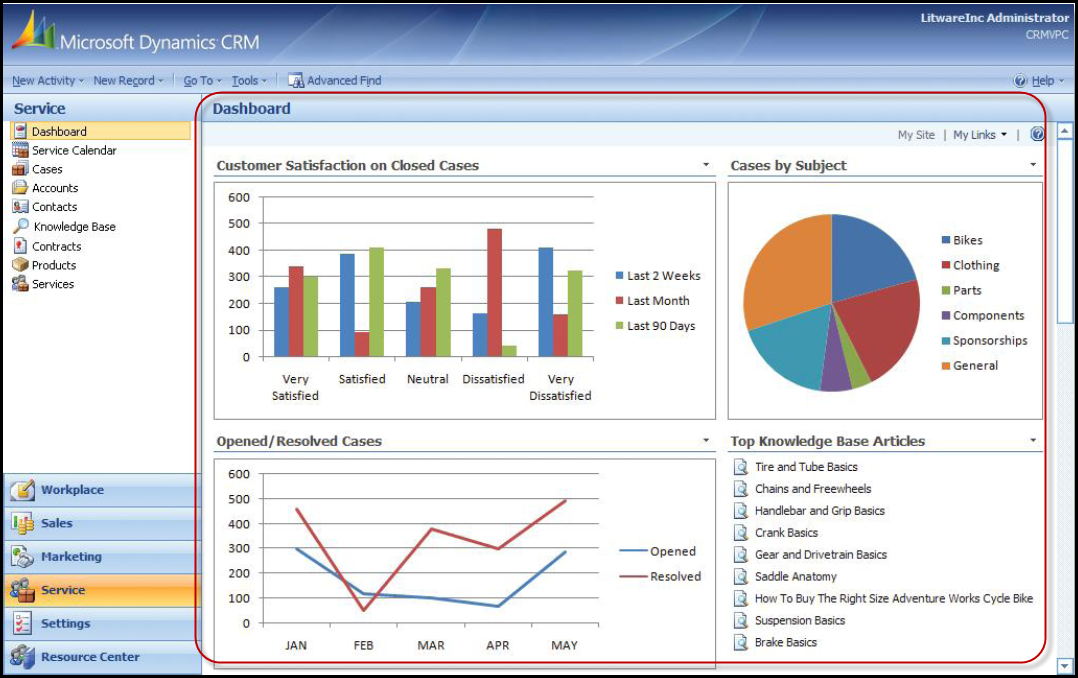
3. Customer relationship management
This is an excellent dashboard showing the CRM functions.
The bar graph shows a good comparison of different types of customers in
different periods. Pie chart shows the cases by subject. The line graph shows
how the number of open and resolved cases increase or decrease every month. It
gives us a trend.
In conclusion, visualization transforms data into information.
Data is on the rise today and this
gave birth to big data. However, with such amount of data available today, it
is not guaranteed that it will be in a desired form for any kind of analysis.
Data is currently available in two forms:
Unstructured Data
This generally refers to any kind
of data that is not stored in a traditional table format and is raw and unorganized.
The data exists in different forms and it is difficult to identify attributes
and derive information from it. Some of the sources of unstructured data are:
Word Processing Files
PDF files
Emails
Digital Images
Audio
Video
Social Media Posts
These files are the means of
communication of data in most of the businesses. The content of these files has
data but it has to be broken down and categorized to understand it.
Structured Data
Structured data is any data which
is stored in some kind of a table, be it a spreadsheet or a database. This data
exists in rows and columns each of which are created with some titles and it is
easy to order and process this data with data mining tools. More emphasis is
given to what fields of data will be stored and how the data will be stored. Structured
data is similar to a filing cabinet which is perfectly organized so that
everything is identified, labeled and easy to access. Some examples of
structured data:
1. Machine
Generated
Sensory
Data - GPS data, manufacturing sensors, medical devices
Point-of-Sale
Data - Credit card information, location of sale, product information
Call Detail
Records - Time of call, caller and recipient information
Web Server
Logs - Page requests, other server activity
2. Human Generated
Input Data
- Any data inputted into a computer: age, zip code, gender, etc.
This video explains more about the
differences between structured and unstructured data:
Data in organizations:
·Dell
survey shows structured data represents at least 75 percent of data under management for the majority of
organizations
·Nearly
one-third of companies surveyed still don’t actively manage unstructured data
·83 percent
of organizations cite growth in transactional data (including e-commerce) as
one of the most important sources of structured data growth within their
organization, with 51 percent also
citing growth in management data, such as ERP systems.
·Although
there is an increasing industry focus on the proliferation of social data, an
increase in the creation of internally generated documents was seen as the top
driver of unstructured data growth, identified by more than 50 percent of
respondents.
An example of how the data can be
analyzed using a data warehouse is as shown:
This primarily involves extraction
from the original data source, performing transformations to suit different
data sources and finally load into a separate database (ETL).
Limitations
of data warehousing:
Some of the limitations of using a
data warehouse are:
·The transformations from
individual data sources to the data warehouse usually represents 50% of the total
data warehouse effort
·Data owners lose control over
their data, raising ownership (responsibility and accountability), security and
privacy issues
·Initial implementation time is
high and expensive
·Updating to add new data sources
is time consuming and expensive
·Limited flexibility since it
requires multiple separate data marts for multiple uses and types of users
·Data is static and dated and
changes cannot be monitored
·No data drill-down capabilities
Future
of data warehousing (supernova schema):
According to Kimball, data
warehousing has never been more valuable and interesting than it is currently
in the age of big data. Since dimensions are the most important part of a
warehouse, they need to be more powerful to support advanced queries and
analytics. In a supernova schema, attributes of a dimension can be complex
objects and not just simple text. Supernova dimensions become much more flexible
and extensible from one analysis to the other. The following figure shows how a
supernova customer dimension is different from a traditional customer
dimension.






{kind=link}